6. Technology
If the interface is the most visible element of the search experience, then the search technology (search tech for short) is the most misunderstood. It is the search tech, along with content—the other overlooked element—that most influences the quality of the search experience.
For example, an important job of search tech is to infer the meaning of a query. So if a user searches for ‘tenders’, then the tech and some human assistance should be able to infer that tenders, tenders, notices, quotations, quotes, project invitations, etc., refer to the same thing. And since the query is a single term without qualifiers, perhaps the user is looking for a page listing all the tenders (a topic page of sorts). A good search tech can easily offer such experiences.
Business and IT people misunderstand search tech for a couple of reasons. First, they believe that search is a utility item—you switch it on and forget about it. Second, they think that the search engine is the search tech. They are surprised to hear that the search tech is a stack of technologies that, besides a search engine, may include text analytics, taxonomies, search analytics, visualisation and much more.
Don't blame the business and IT people for making such assumptions; blame the search tech vendors. They took advantage of the organisation's lack of search knowledge to peddle their products, promised Google-like search performance out of the box, and built a great wall of search ignorance that has withstood the march of understanding for a long time.
The good news is that the wall is showing signs of crumbling. The deluge of big data and the need to tame it has again put search tech in the limelight. Emerging technologies like machine learning and GenAI are forcing business and IT people to reassess how they design, implement and manage search tech.
Let’s now look at some critical components of the search tech stack.
Taxonomies
Taxonomies and associated vocabularies such as thesauri and dictionaries provide the semantic structure to make sense of content. These are created by humans and exploited by machines to offer relevant results to users. For example, the text of an article on football does not reveal much about the sport. But the taxonomy of sport can add that ‘football’ and ‘soccer’ mean the same thing (unless you are in the US, where football is an entirely different sport) and involves kicking a ball with the foot to score a goal.
For more information on taxonomies and other semantic concepts, check out our book on Organising Digital Information.
Text analytics
Text analytics has a powerful cluster of technologies to extract meaning and add structure to unstructured content. It uses rule sets and natural language computations to analyse the content, extract named entities, facts and summaries, and offer insights via clustering and sentiment analysis. It can also use taxonomies to auto-categorise content. For example, text analytics can check if a document is about football played in the US and then categorise it under ‘American football’. Tom Reamy’s book, Deep Text, offers an easy introduction to text analytics.
Search engine
The search engine uses a ranking algorithm to surface the most relevant documents. In the simplest form, when a search is executed, the user’s query is compared against all the documents in the collection, and each document is given a score for how well it matches the query. The documents are sorted using this score, and the top results are returned.
The quality of the search results is highly correlated to the quality of the content. For example, you can index 100,000 documents without enhancements and offer ordinary search experiences. However, you can also pass the collection through taxonomies and text analytics and deliver relevant, specific, extraordinary search experiences.
Search analytics
Search analytics measures how the search is performing. It collects terms people use, results they view and actions they take. It also finds terms that get zero results or a low number of results. The benefit of analysing search performance is that tweaks can be made to close any gaps. This way, search analytics and relevancy tuning go hand-in-hand. For example, if search analytics finds that people searching for ‘hotline’ are getting zero results, adding it as a synonym for ‘contact’ (tuning) can solve the issue.
A key benefit of search analytics is that it can provide feedback to taxonomies and text analytics configurations. For example, the word "hotline" can be offered as a synonym for the taxonomy system so that it is also in sync with ground realities.
An example
Consider a collection of news articles. The users of this collection are policymakers who need to keep track of events and agreements between countries. One of their top queries is to study meetings between political leaders. Knowing this background, how can we create a search experience that helps users get their job done in a simple, helpful way?
Consider a sample query: obama meets indian pm
What would a vanilla search engine deliver? It would show top-ranked articles for the keywords in the query. But that isn’t very helpful to our policymakers. Consider this alternative.
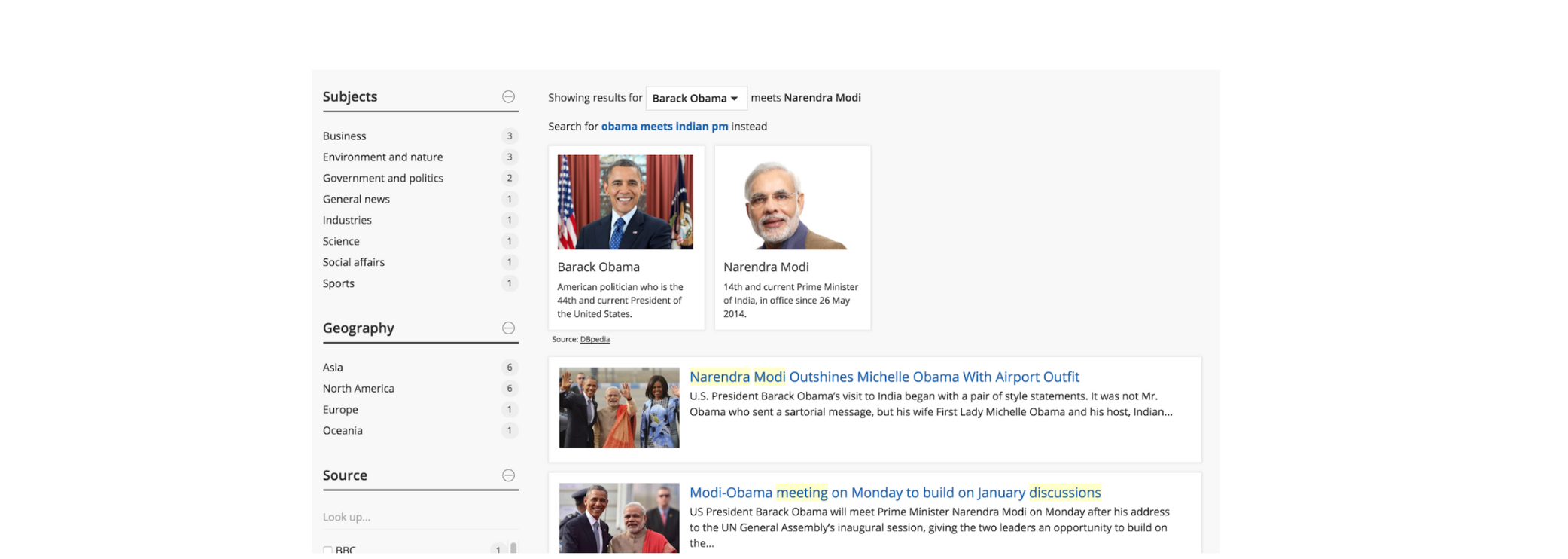
Search results for the query: “obama meets indian pm”
In the screenshot above, the user gets the profile pictures of the two leaders with their full names. The search results use these names to query the collection and, therefore, get more relevant results. The filters on the left offer the user semantic handles to refine the query. How is all of this done?
Here are the steps that the search tech takes:
- Processes the query to identify named entities such as people and places mentioned (text analytics).
- Looks up the acronym 'pm' against a taxonomy to find its expanded form.
- Identifies the entity 'indian pm' as a person and looks it up in the taxonomy, which returns 'Narendra Modi'.
- Does the same for the person 'obama', which actually returns two results 'Barack Obama' and 'Michelle Obama' (the user is given the option to select the correct Obama).
- Modifies the search query to include the names of the entities involved to return relevant results.
- Looks up the entities 'Barack Obama' and 'Narendra Modi' in DBpedia to get their photos.
- Creates filters based on the taxonomic terms they are tagged with.
Finally, search usage is analysed to check what queries are used and to refine where necessary.
Imagine if the search tech could work magic for each top intent in your team, department and organisation. People will be more efficient in their jobs and more happy in their lives.
AI-powered search stack
With large language models (LLMs) and GenAI all the rage these days, how does this impact the search stack?
LLMs are trained on the internet, not on enterprise content. We can't use vanilla LLMs to offer enterprise search. We must add enterprise content with all its access rights and other requirements to the LLM. That is what Retrieval-augmented generation (RAG) offers. RAG methods use all the benefits of LLMs and GenAI but apply them to specific resources, such as enterprise content.
However, LLMs generate responses based on probabilities, which can sometimes lead to imprecise or irrelevant answers. They might "hallucinate" information that sounds plausible but is incorrect. A formal taxonomy helps in grounding the results.
High-quality enterprise content will give better RAG results. Therefore, though the LLMs and GenAI can play the taxonomy and text analytics roles themselves, having a formal taxonomy increases the accuracy and efficacy of the results.