4. Content
If the search interface is the most visible and familiar element of the search experience, then the quality of the indexed content is the most overlooked. Good quality content is critical for creating amazing search experiences. The challenge is first being aware of the correlation.
Search still has a ‘magic box’ appeal to many in the enterprise. They feel that search should work with any content. Again, they cite Google as an example. Little do they know that web publishers these days work hard to create good quality, web-friendly content so that it can rank high in Google search results.
For example, Google rewards pages that follow good HTML markup practices, such as using the <title> and <h1> tags for structure and those that use schema.org for marking up data in the pages such as <Place> and <PostalAddress> for describing locations. There are over 800 types listed on schema.org, and new ones are regularly added.
Comparatively, in the enterprise, much of the content is messy. Structure and markup are nonexistent, and content is hidden away in PDF and Word documents. Users looking for ‘revenue projections for 2022’ may see an ‘Annual Report’ PDF file suggested, not because the search algorithm has gone bonkers, but because the PDF document contains a table listing the year’s revenue projection figures. But is that the correct document from which to get such data? Does it pass the CRAAP (Currency, Relevance, Authority, Accuracy, and Purpose) test?
A chart with an accompanying data table is a much better way of responding to the query on revenue projections. But you must draw the data from the PDF or connect directly to the financial system housing the data. You would go through this trouble if getting revenue projections was a designated top task—vital information that many people in the organisation need. You would ensure that the content correctly represents such tasks.
The process of optimising content to meet search tasks is sometimes referred to as content modelling. It involves cleaning and enriching the content.
You can think of content as a table of rows and columns. Each row is a resource. It could be a single document, such as the Annual Report, or a piece of information, such as the Revenue Projections 2022. The columns are metadata or dimensions such as Publish date or Financial year. The entire table is called a dataset or collection.
Your datasets can be metadata-rich or metadata-poor based on your top search requirements. If, for example, a document does not have Publish Date metadata, then it isn't easy to know whether it is the most recent.
But you say that the date the document was published is mentioned in the body of the document. Why can't we pick that up and add it under the Publish Date?
Yes, that can be done. It is a process called data enrichment— extracting stuff from the body and using it as metadata. All this new metadata is then added to the search index to meet the demands of the search tasks.
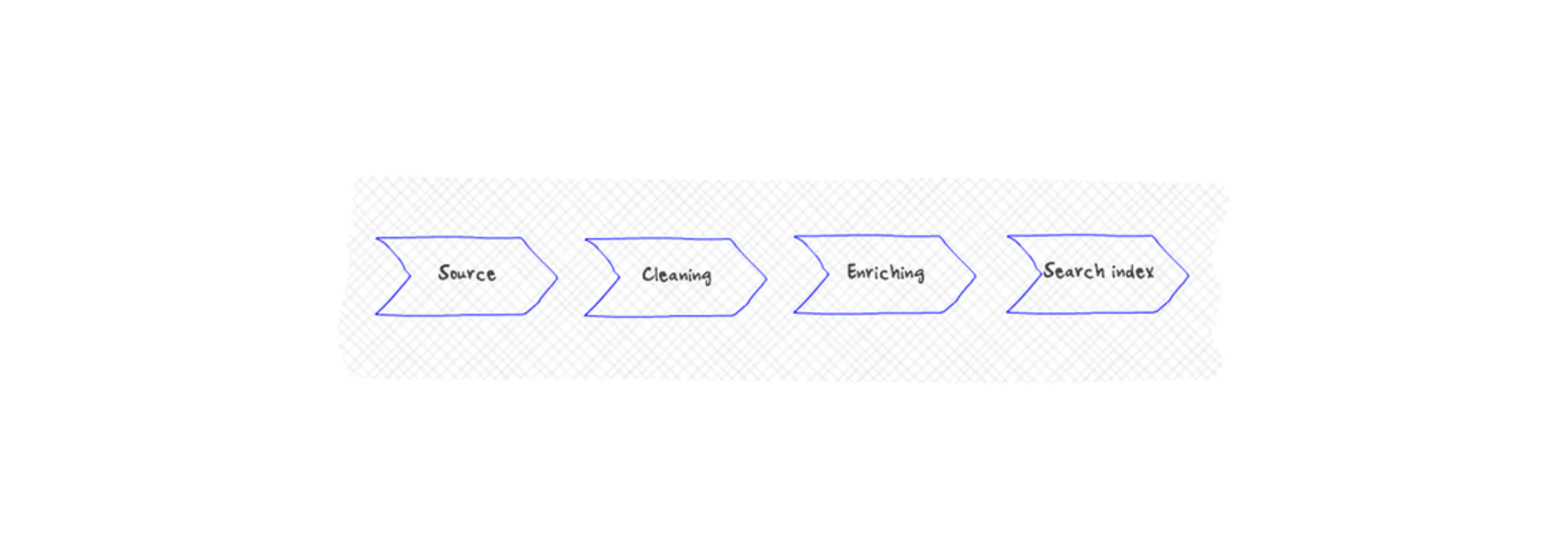
Content enrichment pipeline
With the advancement of machine learning, it is now possible to extract names, places, dates and times from unstructured text. One can even create and assess the sentiment of the text. The discipline of text analytics is now a deep and mature practice.
Worked example
Let’s say we have a news collection (shown below). Now, let’s also assume we researched and found that users are looking for specific things, like TV shows, celebrities and companies. The source format is too flat to answer such queries, so we need to enrich it.
| Metadata | Value |
|---|---|
| Id | 03597bc6-d4fa-43c2-89e0-31fa0fab3997 |
| Title | ‘Late Show with Stephen Colbert’: When it debuts, and why we (and Stephen) can't wait |
| Content | Tuesday night brings the long-awaited debut of \"The Late Show with Stephen Colbert,\" as the host drops his \"Colbert Report\" persona, and welcomes his first guests, George Clooney and Jeb Bush, and musical director Jon… \r \nThe debut of \"The Late Show with Stephen Colbert\" finally arrives Tuesday night, after what seems like an eternity of Colbert teasing us with clips… |
| Source | MyInforms |
| Published | 2015-09-07T18:38:23Z |
| Media type | News |
Based on the requirements, we create new columns using text analytics (shown below).
| Metadata | Value |
|---|---|
| Id | 03597bc6-d4fa-43c2-89e0-31fa0fab3997 |
| Title | ‘Late Show with Stephen Colbert’: When it debuts, and why we (and Stephen) can't wait |
| Content | Tuesday night brings the long-awaited debut of \"The Late Show with Stephen Colbert,\" as the host drops his \"Colbert Report\" persona, and welcomes his first guests, George Clooney and Jeb Bush, and musical director Jon… \r \nThe debut of \"The Late Show with Stephen Colbert\" finally arrives Tuesday night, after what seems like an eternity of Colbert teasing us with clips… |
| Source | MyInforms |
| Published | 2015-09-07T18:38:23Z |
| Media type | News |
| People | Stephen Colbert George Clooney Jeb Bush Marshall Mathers David Letterman Stephen Sondheim Beverly Hilton |
| State | Michigan |
| Television Show | The Late Show |
| Television Company | CBS |
| Facility | Beverly Hilton hotel ballroom |
| Organisation | Television Critics Association |
As you can see, search now has many hooks it can leverage to answer specific queries. The enrichments help improve search relevancy and satisfaction.
Search is as good as the quality of the available content. If the content is messy, search can’t magically make sense of it. You need to model the content to meet specific needs. The repertoire of methods explained in this article offers an opportunity to design amazingly effective search experiences.